Zesen Liu
About Me
I am a Master’s student in the SPAR group at the Institute of Computer Software, Nanjing University.
I am currently working under the supervision of Professor Yanyan Jiang on reasoning about software’s performance characteristics in complex environments (e.g., mobile systems). My research interests also include analyzing and building high-performance solutions for heterogeneous platforms, including FPGAs and GPUs.
Trying to stay ready to conceive (and implement) crazy ideas in the performance aspect!
Recent Posts
- Loading...
News
- [Oct. 2025] I will be attending SOSP'25 at Seoul. Find me at PACMI Workshop.
- [Aug. 2025] I gave a talk “From Assembly to PyTorch: Full-Stack Design and Optimization of DeepSeek Operators on the AMD MI300X” (slides in Chinese) at the AMD Developer Meetup & Workshop 2025 along with my teammates Yankui Wang and Yingyi Hao.
- [Jun. 2025] Our team RadeonFlow won the $100,000 Grand Prize in AMD Developer Challenge 2025 for developing high performance GPU kernels (FP8, MoE, and MLA) on AMD Instinct MI300X — awarded in San Jose by AMD CEO Dr. Lisa Su (YouTube)!
- [Apr. 2025] NanoPulse, a push-based, late materialization database join pipeline for performance research is now open-sourced.
- [Nov. 2024] We presented DomCast, a remote rendering solution built on OpenHarmony, showcasing a new approach to smooth and low-overhead screencasting.
- [Jul. 2024] I led PowerSheet project, a powerful AI synthesizer for spreadsheets running on AMD Ryzen NPU, which won 1st place in the Pervasive AI Developer Contest.
- [Jun. 2023] My undergraduate thesis “FPGA-Accelerated Sparse Cholesky for Graph Optimization on Heterogeneous Systems” (in Chinese) received the Outstanding Undergraduate Thesis award at South China University of Technology (it is one of my favorite research projects!).
Education
Nanjing University, Nanjing, China
Sep 2023 – Jul 2026 (expected)
M.S. in Computer Science & Technology — Institute of Computer Software
Advisor: Yanyan Jiang
Advisor: Yanyan Jiang
South China University of Technology, Guangzhou, China
Sep 2019 – Jun 2023
B.Eng. in Computer Science & Technology — Embedded & Intelligent Robotics Lab
Advisor: Sheng Bi
Advisor: Sheng Bi
Publications
-
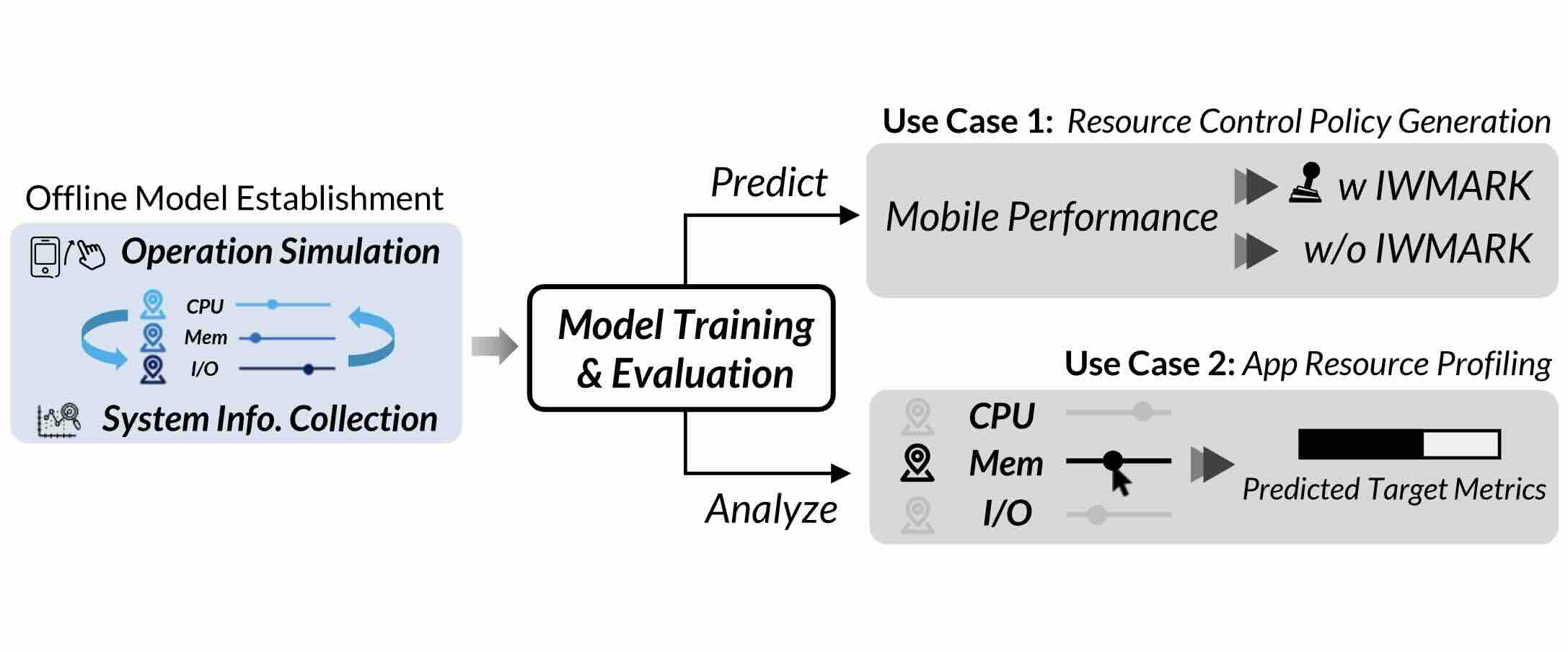 PACMI
Proceedings of the 4th Workshop on Practical Adoption Challenges of ML for Systems (PACMI), 2025.
PACMI
Proceedings of the 4th Workshop on Practical Adoption Challenges of ML for Systems (PACMI), 2025.
Selected Projects
-
 FP8 GEMM, MoE, and MLA kernels tuned for AMD Instinct MI300X. The MoE kernel combining expert-centric token packing, hipBLASlt Grouped GEMM, and low-overhead reverse permutation to maximize throughput. The kernels deliver 8x speedups over AMD’s PyTorch references across challenge workloads.Code AMD Developer Challenge Grand Prize Winner Project
FP8 GEMM, MoE, and MLA kernels tuned for AMD Instinct MI300X. The MoE kernel combining expert-centric token packing, hipBLASlt Grouped GEMM, and low-overhead reverse permutation to maximize throughput. The kernels deliver 8x speedups over AMD’s PyTorch references across challenge workloads.Code AMD Developer Challenge Grand Prize Winner Project -
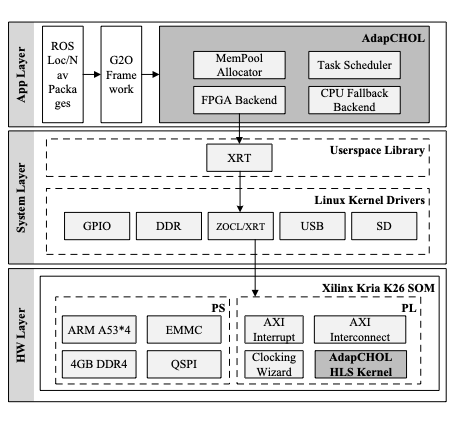 Designed a Cholesky factorization for sparse symmetric positive-definite matrices on Xilinx Kria using HLS. Prioritized low per-factorization latency for typical robot obstacle-avoidance navigation, optimized for small matrices with a fully pipelined load, compute, and store path, delivering up to 148% performance improvement.Code Outstanding Undergraduate Thesis Award
Designed a Cholesky factorization for sparse symmetric positive-definite matrices on Xilinx Kria using HLS. Prioritized low per-factorization latency for typical robot obstacle-avoidance navigation, optimized for small matrices with a fully pipelined load, compute, and store path, delivering up to 148% performance improvement.Code Outstanding Undergraduate Thesis Award -
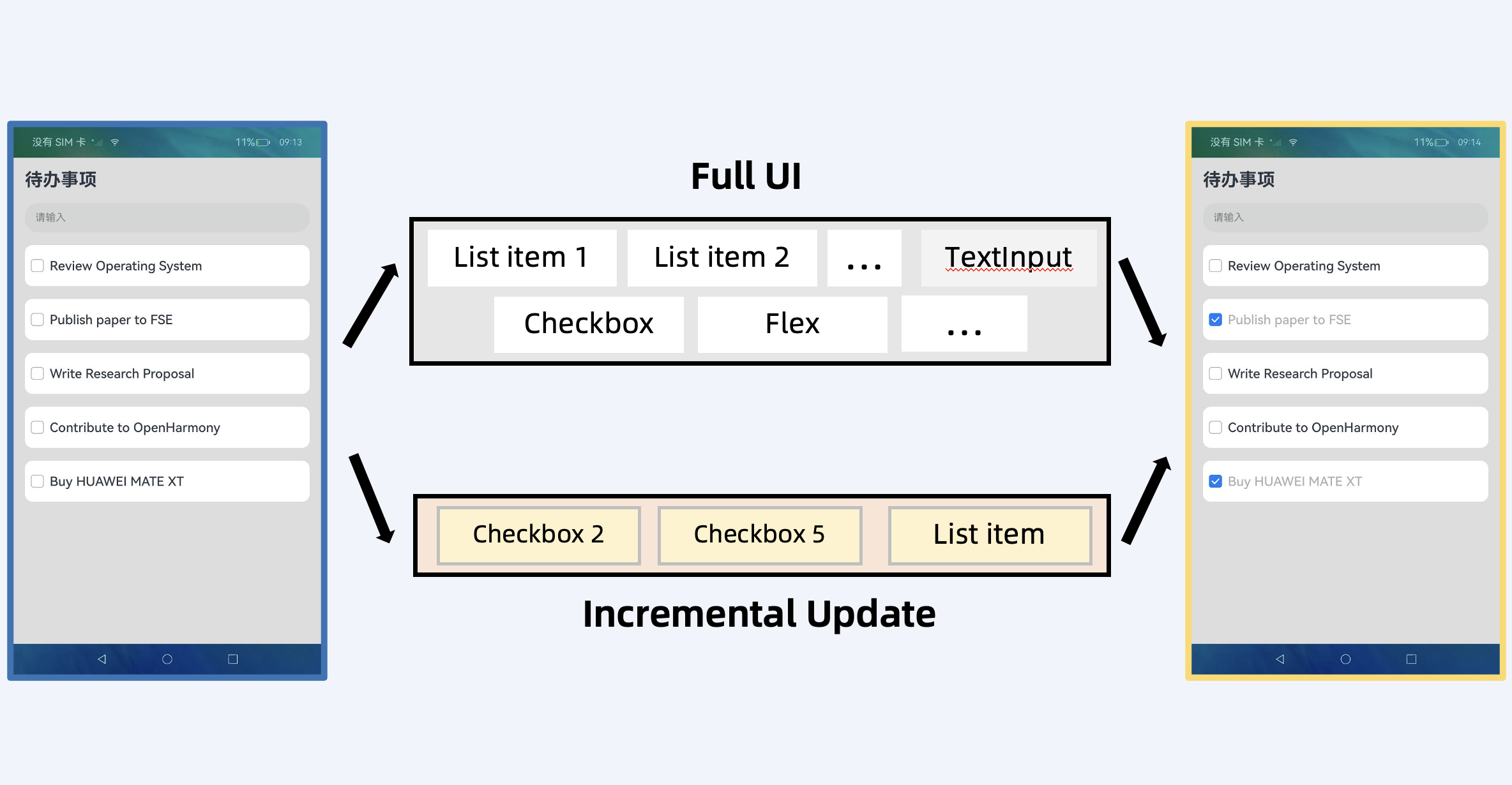 DomCast: Towards Remote UI Rendering on OpenHarmonyDomCast captures UI update events and streams compact UI/state patches to the receiver, which performs layout and rendering, avoiding video encode/decode and achieving low-latency, low-bandwidth mirroring (up to 80x compression on UI deltas). Auto falling back to region-aware JPEG tile casting for highly dynamic apps like games.
DomCast: Towards Remote UI Rendering on OpenHarmonyDomCast captures UI update events and streams compact UI/state patches to the receiver, which performs layout and rendering, avoiding video encode/decode and achieving low-latency, low-bandwidth mirroring (up to 80x compression on UI deltas). Auto falling back to region-aware JPEG tile casting for highly dynamic apps like games. -
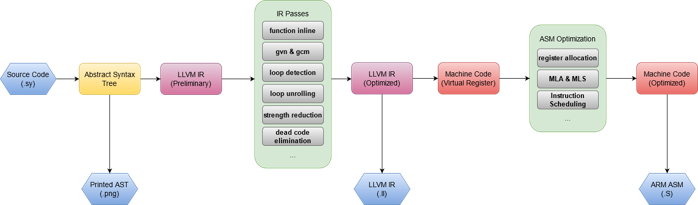 An LLVM IR-compatible C99 subset compiler targeting ARM Thumb with an end-to-end pipeline (AST → IR → ASM). Implements a broad suite of IR-level optimizations—CFG simplification, inlining, tail-recursion elimination, loop unrolling and strength reduction, GVN/GCM, and aggressive DCE. Delivers strong performance while keeping its simplicity.
An LLVM IR-compatible C99 subset compiler targeting ARM Thumb with an end-to-end pipeline (AST → IR → ASM). Implements a broad suite of IR-level optimizations—CFG simplification, inlining, tail-recursion elimination, loop unrolling and strength reduction, GVN/GCM, and aggressive DCE. Delivers strong performance while keeping its simplicity.
Hobbies
- Flying a flight simulator (Yeah – I once wanted to be a commercial airline pilot :P)
- Amateur Radio: I am a licensed amateur radio operator (callsign: BA4SXJ). Hope to catch you on the air. 73!
Powered by Jekyll and Minimal Light theme.